 June 21, 2019
June 21, 2019This is going to be a long one - grab a ☕️ and dig in...
Have you ever looked at a piece of JS code and known what the result of executing that piece of code would be, and yet deep in your mind, you knew you had no idea how the result came about. Or perhaps you've looked at some asynchronous code like an on click handler or an AJAX call and wondered how the heck the callback function knew when to fire?
JavaScript is everywhere. In the browser, on the desktop, in mobile apps, in everyday things around us. Atwood's Law seems to fulfill itself more and more each day - "Any application that can be written in JavaScript, will eventually be written in JavaScript."
It's not news that JavaScript's reach extends far and wide and with it, the number of developers who use it on a daily basis, and yet, a deep knowledge of JavaScript is often hard to come by. This is because JS is one of those languages where you can know just enough to get by and never bother to go really deep.
This article is about deepening our knowledge of JS by understanding how our JS code gets executed. These laws are governed by the interaction of the Execution Context, Call-stack and Event Loop. The interplay of these three concepts is what allows our code to be executed. A good understanding of these foundational concepts is crucial in order to understand more advanced stuff such as scopes and closures. Let's step right in.
Whenever you write JavaScript and run it, you are relying on an engine to execute the code for you. This engine can vary depending on the environment you are in and even between different implementations of the same environment. For instance the Chrome browser and Firefox browser use different engines (V8 for the former and SpiderMonkey for the latter).
The engine is what takes your code and executes it. It follows a series of steps - the first of which is to create a global execution context. This global execution context is usually an anonymous function that serves as a space to run all the code you have written.
The Execution Context
var a = 42;
function foo(num) {
return num * num;
}
var b = foo(a);Let's look at a fairly straightforward piece of code. In this sample, we assign a number value to the a variable, we declare a function foo and then we call foo passing in a as a parameter and then store the return value of that function in b. If I asked you what the result of this piece of code is, I'm sure you'd have no problems following along and getting the correct answer. If however, I asked how JavaScript arrived at the answer, you might not be able to give a straight answer. Let's examine the answer to that question together.
The first thing the engine would do, in the code above would be to create an execution context. There are precise steps which the engine follows and there are two phases to this. The creational phase and the execution phase.
The first time the code runs, a Global Execution Context is created. During this creational phase the engine will do a couple of things:
- Create a global object. This object is for instance, called
windowin the browser orglobalin Node. - Create a
thisobject binding which points to the object created above. - Set up a memory heap for storing variables and function references
- Store function declarations in the memory heap above and store every variable within the context with
undefinedbeing assigned as the value.

In our example, during the creational phase, the engine will store the variables a and b and the function declaration foo. It will also assign undefined to both variables initially.
After this phase is done, the engine moves to the execution phase. During the execution phase, the code is run line by line. It is in this phase that variables are assigned their values and functions are invoked.

If there are no function calls in your code, the story ends here. However, for every function you call, the engine creates a new Function Execution Context. This context is identical to the one above, but instead of creating a global object, this time around an arguments object is created containing a reference to all the parameters passed into the function.

To return to our example above, during the execution phase, the engine would first get to the variable declaration, a, and assign the value 42 to it. Then it would move on the line where we assign a value to b. Seeing that that line makes a function call, it would create a new Function Execution Context and repeat the steps it followed above (with an arguments object being created this time around).

But how does it keep track of all these execution contexts? Especially in a scenario where there are multiple nested function calls or conditionals? How does it know which one is active or which one has been completely executed?
This introduces us nicely to our next concept - the Call-stack.
The Call-stack
The call-stack is a data structure used to keep track of and manage function execution in a piece of JS code. It's job is to store of all the execution contexts created during code execution and to record which execution context we're actually in as well as those that are still remaining on the stack. When you call a function, the engine pushes that function to the top of the stack, then creates an execution context. From our exploration of the execution context above, we know that this context will either be the global one or a function execution context.
As each function runs, the call-stack pops it off and moves on to the next function until it is empty and all functions have been run.This sequence is known as LIFO - Last In First Out.
When a function is called, a stack frame is created. This is a location in memory where parameters and variables are stored (remember the memory heap we talked about above?). This memory gets cleared when the function returns (implicitly or explicitly) and the whole context then gets popped off the call-stack.
Execution contexts are popped off the stack one by one as they complete execution with each one creating a stack frame and when we throw an error, we get what is known as a stack trace, which is what it sounds like - tracing all the execution contexts from the point of the error through to all the contexts we have passed through.
It is also possible to blow the call-stack by having more frames than the stack is designed to hold. This could happen when calling a function recursively without some sort of exit condition or as I'm sure we have all done at some point in time - when an infinite for-loop is run.
Take a look at this piece of code:
function thirdFunc() {
console.log("Greetings from thirdFunc()");
}
function secondFunc() {
thirdFunc();
console.log("Greetings from secondFunc()");
}
function firstFunc() {
secondFunc();
console.log("Greetings from firstFunc()");
}
firstFunc();
// Greetings from thirdFunc()
// Greetings from secondFunc()
// Greetings from firstFunc()Again, how do we get the result we did?
When we run this piece of code, the first thing the engine does is make a call to the call-stack and place a main() or global() function on the call-stack. This is the main thread of execution of your JS code. The execution context we described in the previous section will enter the creation phase first and then the execution phase will be invoked. When the engine gets to the call to firstFunc() during this phase, the call-stack will be referenced again and the function execution context for firstFunc() will be pushed onto the call-stack on top of main() (Step 2 below).

Now the engine will start to execute firstFunc() since it is at the top of the call-stack. It will in turn create a local execution context and local memory allocation to store the variables, parameters and function declarations in this new context. (The concept of scope is tied to this).
The very first line of firstFunc() calls secondFunc(). At this point, the engine will again reference the call-stack and place secondFunc() at the top of the stack repeating the process again. In secondFunc() the first line again references another function called thirdFunc() and the process is repeated one more time.
Now in thirdFunc(), we do not make any function call, instead we simply console.log the string "Greetings from thirdFunc()". This gets executed and then since there are no more instructions in the function, it returns implicitly. At this point, the call-stack pops thirdFunc() off (Step 4 above) and now secondFunc() is at the to the top of the stack. The engine will continue where we left off and console.log the string "Greetings from secondFunc()". Again, as there are no more instructions in this function, the function will return and call-stack will pop off secondFunc() bringing us back to the execution context of firstFunc() where we continue and log out the string "Greetings from firstFunc()". After executing that code, firstFunc() is popped off and control returned to the main execution context which has no further instructions to execute and will be popped in turn. Once our stack is empty, the program will stops running.
The nature of the call-stack reflects the fact that JavaScript is essentially single threaded and only one execution context can be run at a time. This means that while a function is being executed, the engine cannot run another context at the same time. It also means that every time a function is pushed onto the call-stack, it then becomes the active executing context and takes control flow away from whatever function called it, until it returns either explicitly (with a return statement) or implicitly (when all instructions have been executed).
Now if this was where the story ended, then JavaScript would not be much use in anything but the most trivial of applications and certainly not in a web application with a multitude of concurrent events firing at once - user inputs, resource requests, API calls. Each event would block the other until it had finished running. This would mean that when a function was called - perhaps one making a request to a server for an image - nothing else could happen on the page till that image was loaded. If you clicked a link before the image got loaded, the event would not be handled until after the image got loaded.
So how then do we achieve asynchronous JavaScript with it's illusion of multiple things happening all at once? Enter the event loop.
The Event Loop
As we've seen above, the JavaScript engine can really only do one thing at a time. It starts at the top of our code and works it's way down creating new execution contexts as required and pushing and popping them onto and off of the call-stack.
If you have a blocking function that takes a long time to execute, then the browser cannot do anything during the time that the function is at the top of the call-stack. No new execution contexts or code execution can take place. This means that even user input like scrolls and button click events would not work.
Instead, when we have a function that might take a long time to complete, oftentimes we provide a callback function. This function encapsulates the code we would like to run at a later time when the blocking action (e.g a network call) has been resolved. This allows us to return control to the JS engine and defer the rest of the execution until after the call-stack has been cleared. This is the concept of asynchrony in JavaScript.
Let's tweak our code from before into something requiring this new concept:
function thirdFunc() {
setTimeout(function() {
console.log("Greetings from thirdFunc()");
}, 5000);
}
function secondFunc() {
thirdFunc();
console.log("Greetings from secondFunc()");
}
function firstFunc() {
secondFunc();
console.log("Greetings from firstFunc()");
}
firstFunc();
// Greetings from secondFunc()
// Greetings from firstFunc()
// approx. 5 seconds later...
// Greetings from thirdFunc()In the code above, the execution begins as in the previous example. When the engine reaches the third function however, instead of immediately logging the message to the console, it invokes setTimeout() which is an API provided to us by the browser environment. This function accepts a "callback" function which will be stored in a structure we have not discussed yet called the callback queue. thirdFunc() will then complete it's execution, returning control to secondFunc() and firstFunc() in turn. Finally after at least 5 seconds (more on this below), the message from thirdFunc() is logged to the console.
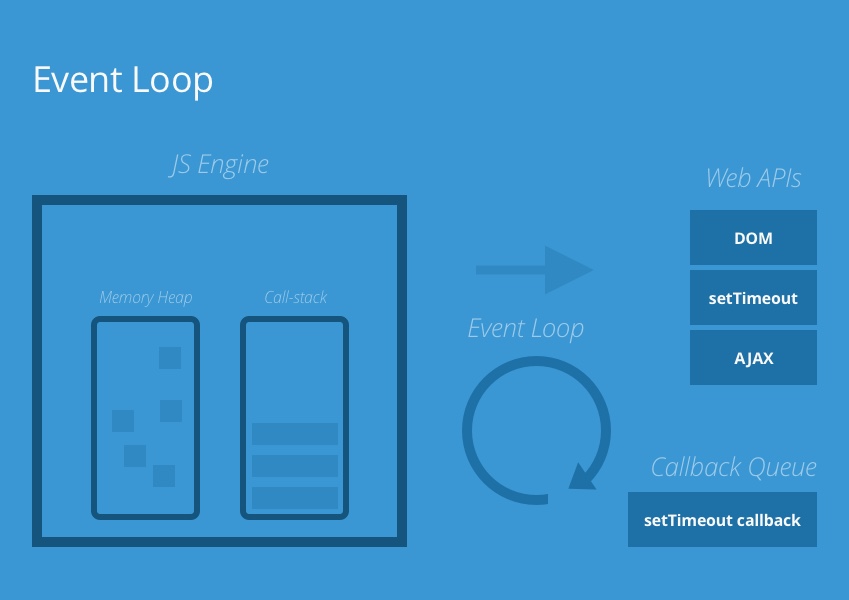
In JavaScript, the mechanism by which we achieve asynchronous execution of code is via environment APIs (Node and the browser both provide certain APIs that expose low level features to us), the callback queue and the event loop,.
Concurrency (or the illusion of it) is achieved via these extra mechanisms.
Just as we said the call-stack was used to keep track of the currently executing function context, the callback queue keeps track of any execution contexts that need to be run at a later time. Such as a callback passed to a setTimeout function or a node async task. While our code is being invoked, the event loop periodically checks if the call-stack is empty. Once the call-stack has run all the execution contexts in our code, the event loop takes the first function that entered the callback queue and places it on the call-stack to be executed. Then repeats the process again continually checking both the call-stack and the callback queue and passing functions from the callback queue onto the call-stack once the call-stack is empty.
Remember when we said the setTimeout callback would run "at least" 5 seconds from the point of invoking setTimeout? This is because setTimeout does not just insert it's code into the call-stack when the timeout completes, it must pass it to the callback queue and then wait for the event loop to place it onto the call-stack when the call-stack is empty. So long as there are still items in the call-stack, the setTimeout callback will not be run. Let's take a look at this in detail.
Our code runs as above until we get to the thirdFunction at this point, setTimeout is invoked, taken off the call-stack and begins a countdown. Our code continues on to secondFunc and firstFunc and console.logs their messages in turn. In the meantime, setTimeout completed it's countdown almost immediately - in 0 seconds - but there was no way for it to get it's callback directly onto the call-stack. Instead when it completed it's countdown, it passed the callback to the callback queue. The event loop kept checking the call-stack but during that time secondFunc and in turn firstFunc occupied space on the call-stack. It was not until these two functions completed execution and the call-stack was emptied, that the event loop takes the callback function we passed to setTimeout and places it on the call-stack to be executed.
This is why sometimes you find the pattern of calling setTimeout with 0 as a way to defer execution of the code in the callback passed to it. We simply want to ensure that all other synchronous code runs before the code in the setTimeout callback.
It's important to also note that a "callback" is a function that's called by another function, but the callbacks we've discussed above, such as the one that is passed to setTimeout are "asynchronous callbacks". The distinction being that async callbacks are passed to the callback queue to await being placed (by the event loop) onto the call-stack for execution at a later time.
And with this, we've covered the major concepts when it comes to JavaScript code execution and how the JavaScript engine handles asynchronous code. We've seen that the JS engine is single threaded and can only execute code synchronously. We've also seen the mechanism for achieving asynchronous code without blocking the thread of execution. We also have a better understanding of the order in which functions are executed and the rules surrounding this process.
These concepts can be a lot to understand but it's worth taking the time to really grasp them as they form the basis for an in-depth knowledge of JavaScript. Not just the var a = 2 syntax but a wholistic view of what exactly happens when JavaScript takes that syntax and runs it. These concepts also act as a building block for a greater understanding of other concepts such as scopes and closures. A subject like this require further resources so feel free to dig in below: